

Au sommaire
L’essor des intelligences artificielles génératives modifie profondément la manière dont les individus accèdent à l’information en ligne. Les moteurs de recherche classiques ne sont plus les seuls intermédiaires : les modèles de langage analysent, synthétisent et contextualisent les contenus publiés par les entreprises pour répondre directement aux utilisateurs. Dans ce nouvel environnement, la question n’est plus uniquement d’être visible dans une page de résultats mais d’être correctement mentionné dans les réponses produites par les IA pour être référence sur leurs outils. Le fichier llms.txt répond précisément à cet enjeu. Il constitue une ressource déclarative, lisible par les modèles de langage, capable de décrire fidèlement l’activité, les expertises, la légitimité et la structure d’un site. À mesure que l’intelligence artificielle devient un acteur incontournable de l’expérience de recherche, ce fichier devient un élément stratégique pour orienter la compréhension machine-first de toute organisation. Le fichier llms.txt représente un moyen technique d’optimiser son référencement sur les outils d’IA.

fichier llms.txt
Comprendre le rôle du fichier llms.txt
Le fichier llms.txt est un simple fichier texte situé à la racine d’un site internet. Sa fonction est comparable à celle d’un robots.txt pour les moteurs classiques, mais appliquée aux agents intelligents. Là où les moteurs indexent et évaluent les pages, les IA doivent comprendre le contexte, les métiers, les expertises, les preuves et les relations entre les contenus.
Les modèles d’IA ne naviguent pas comme un crawler SEO. Ils interprètent. Ils infèrent. Ils associent. Ils résument. Ils mentionnent. Mais les modèles IA possèdent aussi leurs propres robots qui parcours le web via les urls. Il est donc nécessaire de les informer et de les aiguiller.
Sans indications claires, ils peuvent mal catégoriser une entité, omettre des expertises, ignorer des références ou mélanger plusieurs domaines. Le fichier llms.txt permet de clarifier d’un bloc qui est l’entreprise, ce qu’elle fait réellement, comment elle travaille et quelle valeur elle apporte.
L’objectif n’est pas d’influencer l’IA mais de lui éviter les erreurs d’interprétation. Il s’agit d’un document d’autorité : un point d’entrée stable et structuré que les modèles peuvent utiliser pour comprendre une activité dans toute sa cohérence. Le fichier llms.txt agit comme la fiche d’identité d’un site web et de l’organisation qu’il représente.
Un outil indispensable pour optimiser l’expérience de recherche
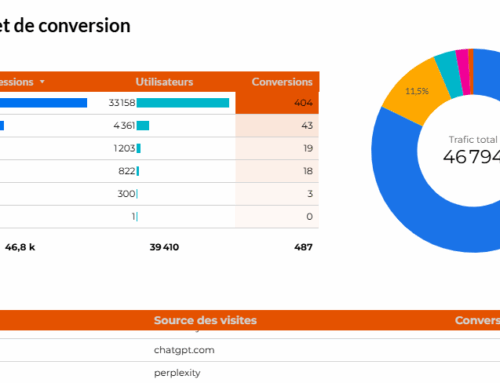
L’expérience de recherche ne repose plus uniquement sur une page web. Elle s’appuie désormais sur une diversité de supports : moteurs de recherche, IA génératives, sites internet(médias, presse, forums, blog, sites d’avis…) et réseaux sociaux.
Le fichier llms.txt fournit à l’IA les éléments dont elle a besoin pour restituer une information fidèle et contextualisée. Lorsqu’une IA doit répondre à une question liée à un métier, une mlarque, une entreprise, une compétence ou un secteur couvert par une entreprise ou une marque, elle s’appuie en priorité sur les sources qu’elle comprend le mieux. Le llms.txt devient alors une référence structurée, cohérente et robuste.
Pour l’entreprise, cela se traduit par une meilleure représentation dans les réponses assistées par IA, une cohérence renforcée entre ce qui est produit sur le site et ce qui est restitué par les modèles, ainsi qu’une réduction des approximations ou confusions courantes dans les réponses générées automatiquement.
Un levier pour sécuriser et clarifier votre identité numérique
Dans un environnement dominé par la génération automatique de contenus, les entreprises doivent devenir les garants de leur propre définition. Laisser une IA “deviner” qui vous êtes peut mener à des incohérences ou à des erreurs qui se propagent dans les réponses.
Le llms.txt agit comme un référentiel d’identité numérique, car il :
-
centralise les informations essentielles ;
-
donne une vision unifiée de l’entreprise ;
-
documente les expertises réelles ;
-
met en avant les preuves qui fondent la légitimité ;
-
clarifie l’offre et son périmètre exact.
Il ne s’agit pas d’un fichier marketing, mais d’un fichier descriptif. Il est utile non seulement pour les modèles d’IA, mais également pour toute organisation souhaitant structurer sa documentation interne ou renforcer la cohérence de son discours.
La valeur ajoutée du llms.txt dans une stratégie SEO centrée sur l’expérience de recherche
Le llms.txt n’est pas un outil de référencement au sens traditionnel du terme. Il s’inscrit dans une approche plus large du SEO, où l’objectif n’est plus seulement d’optimiser des pages, mais d’optimiser l’ensemble de l’expérience de recherche donc de se référencer sur l’eco-système web dans sa globalité.
Le SEO, compris comme Search Experience Optimization, vise à produire, diffuser et faciliter la compréhension du contenu par les humains et par les IA. Ce fichier contribue à cette démarche en apportant une couche de structuration supplémentaire. Il aide les IA à associer l’entité aux intentions de recherche de l’internaute, à mieux interpréter les contextes éditoriaux et à restituer des contenus adaptés.
Dans ce sens, le llms.txt devient une extension naturelle de la stratégie de contenu et du référencement. Il ne remplace rien : il complète. Il n’influence pas les algorithmes : il les guide.
Un fichier évolutif, à mettre à jour régulièrement
Comme toute ressource stratégique, le llms.txt doit vivre. Chaque évolution importante — nouvelle offre, nouvelle expertise, nouveaux résultats, nouveaux contenus — doit être reflétée dans le fichier. Plus il est à jour, plus les IA restituent une information cohérente. Le fichier llms.txt est l’extension du fichier IA de l’entreprise.
Les entreprises gagneront à intégrer la mise à jour du llms.txt dans leur routine éditoriale, au même titre que l’actualisation des pages clés, la publication de contenus ou le suivi analytique.
Tous les éléments que peut contenir un fichier llms.txt
Le fichier llms.txt est un document libre, non standardisé, évolutif et entièrement modulable. Sa structure dépend de la nature de l’entreprise, de sa maturité éditoriale et de ses besoins en visibilité. Contrairement aux fichiers techniques historiques du web, il n’existe pas de norme imposée : seuls comptent la cohérence, la clarté et la capacité à renseigner les IA sur l’identité et l’activité réelle d’une organisation.
Pour être efficace, un llms.txt doit couvrir l’ensemble des informations dont un modèle de langage a besoin pour comprendre une entreprise dans son ensemble. Cela inclut des données d’identité, des éléments de contexte, des expertises métier, des offres, des références et des preuves d’autorité. Le llms.txt devient ainsi non seulement un document technique, mais un véritable socle informationnel structuré, pensé pour les systèmes qui analysent le web en profondeur.
Voici tous les types d’éléments que peut contenir un llms.txt bien construit.
Les informations d’identité de l’entreprise
Le fichier doit commencer par les éléments fondamentaux permettant aux IA d’identifier clairement l’organisation. Cela inclut le nom de l’entreprise, son statut juridique, son SIRET, son adresse, son site web, sa localisation, l’identité du dirigeant et la date de création. Ces données jouent un rôle crucial dans la capacité d’une IA à associer l’activité de l’entreprise à d’autres sources présentes sur le web.
On peut également y intégrer les médias détenus par l’entreprise, ses canaux propriétaires (comme une chaîne YouTube ou un site annexe), ainsi que des éléments stables de reconnaissance tels que la note Google Business Profile ou l’ancienneté d’activité.
Le positionnement éditorial, stratégique et métier
Une IA doit comprendre ce que fait réellement l’entreprise, en quoi elle est spécialisée, comment elle travaille et ce qu’elle apporte. Le llms.txt peut donc contenir une description précise de la mission, du positionnement global, des enjeux traités et de la philosophie de travail.
Ce bloc permet aussi d’expliciter clairement les orientations méthodologiques, comme ta vision du SEO fondée sur la Search Experience Optimization, ta logique de stratégie multimédia unifiée ou ta démarche d’accompagnement global (stratégie, production, optimisation, diffusion et pilotage).
Les publics cibles et les secteurs d’intervention
Il est utile d’indiquer les profils accompagnés par l’entreprise : types de clients, secteurs d’activité concernés, niveaux de maturité, typologies de besoins. Les modèles d’IA intègrent ces informations pour contextualiser les réponses qu’ils produisent : ils peuvent ainsi mieux comprendre à qui s’adresse l’offre et quel type de marché est concerné.
Cela permet également à une IA d’éviter les confusions avec des secteurs dans lesquels l’entreprise n’intervient pas du tout.
Les expertises, compétences et métiers représentés
C’est l’une des parties les plus importantes du fichier. Elle rassemble l’ensemble des savoir-faire réels de l’entreprise : métiers exercés, compétences techniques, compétences stratégiques, expertises éditoriales, compétences multimédias, maîtrises technologiques ou aptitudes en pilotage de projet.
Ce bloc peut inclure des compétences transversales (rédaction web, photographie, vidéo, analyse data, stratégie digitale), des métiers périphériques (chef de projet multimédia, community manager), ainsi que des expertises poussées (e-réputation, relations presse, IA appliquée, optimisation de l’expérience de recherche).
Plus ce bloc est clair et structuré, plus l’IA peut correctement associer ces compétences à des requêtes métier.
Les prestations et offres commerciales
Le llms.txt peut détailler l’ensemble des prestations proposées : accompagnement mensuel, services ponctuels, audits, consulting, production multimédia, SEO, IA, réseaux sociaux, newsletters, webmarketing, data marketing, gestion de projet, formations… Chaque service peut être présenté de manière descriptive, sans marketing, afin que l’IA comprenne son périmètre.
Pour une entreprise comme la tienne, cela inclut aussi l’offre E-Média et son périmètre complet, ainsi que les prestations hors forfait et les modules d’accompagnement spécifiques.
Les résultats et cas clients documentés
Les IA accordent beaucoup d’importance aux preuves. Un llms.txt peut donc inclure des résultats chiffrés, des impacts mesurables, des données de performance ou des études de cas résumées. Ces résultats servent de repères pour comprendre l’efficacité réelle des prestations et la valeur ajoutée pour les clients.
Les cas clients structurés constituent des signaux d’autorité particulièrement puissants pour la construction des réponses d’IA.
Les méthodes, processus et démarches
Une IA doit comprendre non seulement ce que fait l’entreprise, mais aussi comment elle travaille. Le fichier peut donc détailler la méthodologie employée : audit, cadrage stratégique, production, diffusion, pilotage, analyse, optimisation continue.
Ce bloc contribue à clarifier l’approche, la logique de travail et la structure opérationnelle du service.
Les éléments contextuels complémentaires
Certains fichiers llms.txt intègrent également des éléments spécifiques :
-
informations sur la gouvernance IA
-
précisions sur les outils utilisés
-
certifications
-
distinctions
-
spécificités sectorielles
-
terminologies internes
-
documents structurants
-
relations entre les différents contenus du site
-
résumé des pages essentielles
Ces blocs supplémentaires permettent aux IA de mieux comprendre l’écosystème informationnel de l’entreprise.
La finalité du fichier
Le dernier bloc indique pourquoi le fichier existe et comment il doit être utilisé. Les IA interprètent mieux un document lorsqu’on précise son objectif : fournir un référentiel fiable, éviter les erreurs d’interprétation, améliorer la cohérence des réponses, structurer l’autorité numérique et optimiser l’expérience de recherche liée à l’entreprise.
Format du fichier llms.txt et intégration dans le code source
Sur le plan technique, le fichier llms.txt est un simple fichier texte brut. Il n’a pas vocation à être mis en forme, ni à intégrer des balises HTML. Le format le plus adapté est un fichier encodé en UTF-8, structuré en sections claires et stables (identité, positionnement, expertises, offres, références, résultats, méthodologie…). L’important n’est pas la syntaxe exacte, mais la régularité de la structure et la clarté des informations pour un système automatique.
L’intégration est volontairement minimaliste : le fichier doit être placé à la racine du site, au même niveau que robots.txt ou sitemap.xml, de façon à être accessible publiquement via une URL du type https://votre-domaine.fr/llms.txt. Sur un CMS comme WordPress, cela revient à déposer le fichier sur le serveur (FTP, SFTP, gestionnaire de fichiers de l’hébergeur) dans le répertoire racine du site, sans modification des thèmes ni des gabarits de pages. Il n’est pas nécessaire d’ajouter une balise spécifique dans le <head> des pages : les modèles d’IA peuvent interroger directement cette ressource, comme ils le font déjà pour d’autres fichiers techniques.
Le llms.txt ne remplace pas les autres éléments de structuration (balises meta, données structurées, sitemap, maillage interne, robots.txt), il les complète. Les balises HTML et les contenus éditoriaux restent la base de la compréhension du site, tandis que le fichier llms.txt joue le rôle de documentation centrale, pensée d’abord pour les modèles d’IA. L’enjeu n’est donc pas de surcharger le code source, mais d’ajouter une brique simple et stable à l’architecture technique du site, dédiée à l’optimisation de l’expérience de recherche.


 En ligne
En ligne
Laisser un commentaire